





![]() Key takeaways
Key takeaways
✅ Plans built around enterprise frameworks usually fail at 25-250 staff because they assume teams and budgets you don’t have, pick a five-step model instead.
✅ UK GDPR gives you 72 hours from awareness to notify the Information Commissioner’s Office (ICO); the clock starts when you knew, not when the breach happened.
✅ Law firms have a separate seven-day cyber-breach notification window with the Solicitors Regulation Authority (SRA); name it in the playbook or you will miss it.
✅ The most common reason a BCP fails on the day is that nobody ever walked through it together, book the tabletop before you polish the document.
✅ Disaster recovery and business continuity are not synonyms: DR is the IT subset, BCP is the organisational whole, and you need both written down.
Business continuity planning at 25-250 staff is a different exercise to business continuity planning at enterprise scale. The frameworks designed for larger organisations assume teams, capacity, and governance smaller firms typically don’t have. The result is often a planning document that looks compliant but wouldn’t actually help if something went wrong on Monday morning. This is a practical guide to what business continuity planning looks like at your size, the framework that fits, the regulator clocks that may apply, and the failure modes we see most often.
What business continuity planning actually means at 25-250 staff
For a 200-person firm, business continuity planning (BCP) is not the same activity it is for a 20,000-person firm. The enterprise version assumes a dedicated continuity manager, a board-level risk committee, an established testing cycle, and the budget to absorb several months of preparation. None of that scales down cleanly.
At 25-250 staff, what we typically see work is a focused plan that answers three questions clearly:
- What could realistically take your business offline?
- How long can you afford to be offline?
- Who does what if it happens?
The answer to the first question doesn’t have to be exhaustive. The handful of scenarios we see most often, ransomware, prolonged loss of cloud services, a key supplier going under, a serious fire or flood at the office, a critical staff member becoming unavailable, covers most of the realistic risk for a UK SME. You don’t need to plan for every conceivable disaster, and a plan that tries to do so usually never gets finished.
The second question is the one most firms underprice. “How long can we tolerate being down?” is often answered with confident-sounding numbers that haven’t been pressure-tested against payroll, supplier deadlines, regulator clocks, or the day a major client expects an answer. Once those constraints sit on the table, the recovery time objective (RTO) for some systems shortens and others get longer than the original guess.
The third question is the one most often left implicit. A plan that names systems and impact tolerances but doesn’t name people, by role rather than by individual where possible, is a document, not a plan. The person who knows your email tenant inside out should not also be the person who calls your insurer; if the same name appears in every box, the plan needs more depth.
The plan a 50-staff firm needs is short, printable, and walked through twice a year. Anything longer than that gets abandoned the moment the office is on fire.
The five-step framework that fits
The version of BCP we run most often with clients at this size is a five-step cadence. Each step produces a single artefact the team can refer back to without needing to re-read the whole thing.
- Business impact analysis. List the systems and processes that matter, email, file storage, line-of-business application, finance system, payroll, CRM, phones, and assign each a recovery time objective (RTO) and recovery point objective (RPO). The output is a one-page table. The exercise of building it is where most of the value sits.
- Risk register. The scenarios most likely to disrupt the business, with rough probabilities and impacts. Six to twelve items is normal. Listing the same scenario in five flavours is a sign the register hasn’t been thinned out yet.
- Response playbooks. What to do, in what order, when each scenario happens. The most useful playbook is short and printable. The least useful is a fifty-page document that mirrors a Microsoft Word template.
- Communication tree. Who tells whom, in what order, when something goes wrong. Includes external parties: regulators, insurers, key suppliers, your most important clients. The line that gets forgotten most often is “who tells the board, and when”.
- Tabletop test. Once the documents exist, walk through them with the team using a realistic scenario. The point isn’t to follow the plan; it’s to find where it breaks. The questions the team can’t answer are the ones to go back and fix.
We typically deliver the full set in two to three days of work spread over four to six weeks. The team needs time between sessions to gather information, react to first drafts, and run their normal work alongside the planning. Compressing it into a single week tends to produce a plan that’s correct on paper but that nobody on the team feels ownership of.
What goes in the playbook itself
Each response playbook should fit on a single side of A4. Anything longer doesn’t get read in an incident. The minimum useful playbook names:
- The trigger condition (when does this playbook apply?)
- The first three actions, with named roles
- Who escalates, to whom, after how long
- The regulator notification step, if one applies
- The communication tree to activate
If the playbook depends on someone reading a longer document to make a decision, that document needs to be linked, named, and tested for availability
during an incident, not buried on the network share that’s just gone offline.
What we typically see go wrong
Three patterns recur across the firms we work with at this size. Each one is cheap to fix once it has a name.
Single IT person bottleneck. The plan effectively lives in one person’s head. If they’re on holiday, unavailable, or themselves caught up in the incident, the plan doesn’t really exist. Documentation is the fix, but only if the documentation is actually maintained, a runbook last updated three years ago is worse than no runbook, because it implies a confidence the team doesn’t actually have. We typically suggest naming a deputy in writing and rehearsing the deputy through the tabletop, not just the primary.
Undocumented supplier dependencies. Many SMEs run on a handful of cloud services and SaaS tools, Microsoft 365 or Google Workspace, a CRM, a finance system, a sector-specific application, a backup provider, a managed security service, but the list of those tools, their support contacts, and the contractual recovery commitments isn’t accessible from anywhere except the IT lead’s email. A simple vendor register, updated quarterly and stored somewhere that survives a primary-tenant outage, addresses this. The register should name the support number, the contract reference, and the contracted recovery point.
No tabletop test. The plan looks complete on paper but has never been walked through with the team. The first time you run it should not be when something is actually on fire. The tabletop is also where the executive team sees the plan; without that visibility, the response on the day becomes confused about who has authority for which decisions.
A plan that hasn’t been tabletop-tested has not yet been pressure-tested. The cost of the test is half a day. The cost of finding out the plan has a gap during a real incident is, in our experience, considerably more.
A fourth pattern shows up less often but has the highest cost when it does: assuming your insurer’s claims response is part of your continuity plan. It isn’t. Cyber insurance typically pays for forensics, legal advice, and ransom negotiation if covered, but the policy is not the same thing as a response plan, and the
response in the first hours of an incident is yours regardless of whether the claim is eventually accepted.
Regulator clocks UK firms should build into the plan
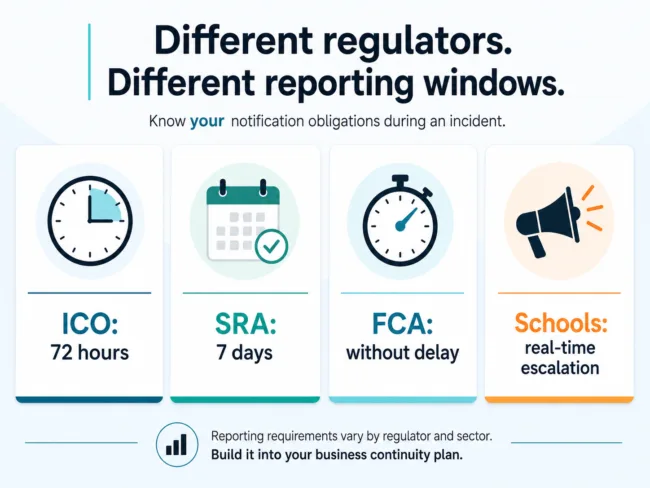
UK regulatory frameworks introduce time-bound notification requirements that the business continuity plan should reflect explicitly. The four we reference most often with clients:
| Regulator | What it covers | Notification window |
| Information Commissioner’s Office (ICO) | Personal data breaches under UK GDPR and the Data Protection Act 2018 | 72 hours from awareness |
| Solicitors Regulation Authority (SRA) | Material events affecting client confidentiality for law firms | 7 days |
| Financial Conduct Authority (FCA) | Important business service outages under Operational Resilience (PS21/3) | “Without delay” plus reporting tolerances set per service |
| Department for Education (KCSIE) | Safeguarding-data continuity for schools and colleges | Per the 2024 update, escalation to designated safeguarding lead in real time |
Three points worth naming. First, the ICO clock starts from awareness, not from when the breach occurred, the first hours are about establishing what you know and what you can reasonably notify. Second, the SRA window is longer than the ICO window for the same incident, so a law firm with a personal-data-affecting cyber incident has both clocks running simultaneously; the playbook should name both. Third, FCA Operational Resilience expects firms to have identified their important business services in advance, set impact tolerances against each, and tested recovery, it’s not a one-off notification, it’s a continuous-readiness regime.
The Cyber Security and Resilience Bill (CSRB) is expected to extend cyber resilience and incident-reporting duties to a wider range of organisations, and will likely add a further notification window for in-scope firms when it passes. Plans drafted today should be structured so a new line can be added to the regulator table without rewriting the playbook.
Building the regulator notification step into your response playbooks is one of the cheapest improvements available. Most firms that miss a regulatory deadline do so because the playbook never named it, not because the deadline itself was unreasonable.
Sector-specific risks worth naming in the plan
Different sectors carry different continuity exposures. The plan should be honest about which apply to you rather than treating every scenario as equally likely.
- Charities. Donor-data confidentiality and grant-deadline pressure dominate. A breach that delays a funder report can affect cash flow in a way the average commercial firm doesn’t experience. The Fundraising Regulator and the Charity Commission both have their own notification expectations.
- Law firms. SRA seven-day reporting, client confidentiality obligations, and the fact that case-management systems often run on small SaaS vendors with limited published recovery commitments. The continuity plan should know what your case-management provider’s recovery point and time commitments actually are, not what you assume.
- Schools. KCSIE 2024 strengthened expectations around safeguarding-data continuity. The plan should name where pupil safeguarding records live, who has access during an outage, and how the designated safeguarding lead is reached if normal channels are down.
- Financial services. Operational Resilience under PS21/3 is the dominant framework. FCA-regulated firms should have a list of important business services with impact tolerances per service, and the tabletop should test recovery against those specific services rather than against generic IT scenarios.
- Professional services more broadly. Accountancy, consultancy, and surveying firms typically face client-deadline pressure as the operational continuity constraint that outweighs regulator concerns. The plan should name which client deadlines you cannot reschedule and which you can.
A plan written generically, without naming the sector-specific obligations that apply to you, usually compresses to the same five-step framework. The sector layer is what makes it operationally useful rather than merely conceptually complete.
BCP and disaster recovery, what differs and why both matter
Business continuity planning and disaster recovery (DR) are frequently used interchangeably in conversation. They are not the same thing, and treating them as synonyms is one of the more common failure modes we see.
| Business continuity planning | Disaster recovery |
| Organisational scope, how the firm keeps operating | Technical scope, how IT systems and data are restored |
| Includes communication, decision-making, non-IT functions | Focused on infrastructure, backups, failover, replication |
| Output: playbooks, communication trees, tabletop tests | Output: RTOs, RPOs, backup tests, runbooks |
| Owned by the business, typically a senior leader | Owned by IT, typically the IT lead or MSP |
DR is a subset of BCP. A firm with a strong DR plan but no continuity plan can technically restore its systems within target windows but may still be unable to function, because the people who know what to do next aren’t reachable, or because the supplier chain to operate the restored systems has its own outage, or because the regulator deadlines weren’t notified during the recovery window.
Conversely, a firm with a strong continuity plan but weak DR will know exactly who needs to do what, but the underlying systems won’t come back fast enough to meet the response windows the plan assumed.
The mature stance is to treat them as two halves of one capability, owned by two different people who meet at the boundary. Most plans we see fail at the boundary, not within either domain.
Where ramsac tends to fit in (and where it doesn’t)
Most of the work above can be done in-house if you have someone with the time and relevant experience. Where we tend to add value is in the structuring, the business impact analysis template, the playbook format, the tabletop facilitation, and in the cybersecurity-specific scenarios where our incident response
experience is directly relevant: ransomware response, data breach notification, supplier compromise.
We tend not to take ownership of the plan day to day. That stays with the client. Our role is to help build it, test it, and refresh it as the business changes. A continuity plan owned by an external partner that the firm has no ongoing engagement with becomes stale the first time the org chart changes, and we’d rather build something the team can maintain than something that depends on us.
There are two situations where deeper involvement makes sense. The first is when an incident is in progress and the firm wants experienced hands during the response, that’s a different engagement, not BCP advisory. The second is when the cybersecurity dimension of continuity is the operational priority and the firm has signed up to our managed cybersecurity service; in that case the continuity planning sits inside the standing engagement rather than as a one-off project.
If you’re not sure which side of that line your firm sits on, a discovery conversation is the right first step. It’s free, it takes thirty minutes, and the output is honest about whether you need our help at all.
Next step
Book a 30-minute business continuity discovery call. We’ll walk through the systems most critical to your operations, sketch out where your current planning sits on the five-step framework above, and identify the cheapest two or three improvements you could make this quarter.
👉 Book a 30-minute BCP discovery call

How can we help you?
We’d love to talk to you about your specific IT needs, and we’d be happy to offer a no obligation assessment of your current IT set up. Whether you are at a point of organisational change, unsure about security, or just want to sanity check your current IT arrangements, we’re here to help.
FAQs: Business Continuity Planning
For most organisations of 25-250 staff, an annual tabletop exercise is the right cadence, supplemented by an informal review after any genuine incident.
Quarterly testing is rarely justified at this size and tends to produce fatigue rather than learning. FCA-regulated firms have specific testing obligations under Operational Resilience that may require more frequent exercises against important business services.
Disaster recovery is the technical side: how IT systems and data are restored after a failure. Business continuity is broader, it covers how the organisation keeps operating, including communication, decision-making, and non-IT functions. DR is a subset of BCP, not a synonym, and most firms need both written down by different owners.
Probably yes, but a smaller one. Even at 25 staff, the founder hit by a ransomware attack who hasn’t written down how to respond will spend their first eight hours figuring out questions a one-page playbook would have answered.
Cyber Essentials is a baseline cybersecurity certification, it tests whether you have the five core technical controls. Business continuity planning is broader and complementary. Cyber Essentials Plus and ISO 27001 both touch on continuity planning, but neither replaces a proper BCP exercise.
The insurer should appear in the communication tree, with a contact route that doesn’t depend on your primary email tenant. The insurer is not, however, a substitute for the plan, the response in the first hours is yours regardless of whether a subsequent claim is accepted, and most policies expect a documented continuity plan as a precondition for cover.
